从去年四月被师兄带入差分隐私(differential privacy:DP)的大坑算起,一直到现在,也有快一年的时间了。这一年中自己一个人闷头看论文,想 idea,码实验,写论文,走了不少弯路,在大大小小的坑中摔了好几次,最终写完了一篇小论文,我也有点想告别差分隐私,去寻找其他的更具工程性和实验性(empirical)的研究方向了。
在与差分隐私挥手告别之前,请允许我再回顾一下差分隐私在我心目中的形象吧~
总得来说,差分隐私是一个理论性很强的概念,他不像深度学习那么 “黑盒”,也不像其他工程上的隐私保护机制(例如 Tor 网络)那么清晰直观易懂,而是靠严格限定的模型和可证明的概率约束条件来实现隐私保护的。
Differential Privacy#
差分隐私所防范的是差分攻击,其起源于数据库领域,描述了一套攻击者推断数据库中具体数据变化情况的过程。
Model#
考虑两方:
- 数据库维护者(curator):他拥有完整的数据库(例如关系型数据库),其中每一条都是关于一个用户的个人信息;他向第三方只提供聚合查询接口(函数)$f$(例如 count,sum,max)。
- 攻击者:基于已有的知识,尝试通过 curator 提供的接口查询得到数据库中单个记录的情况。
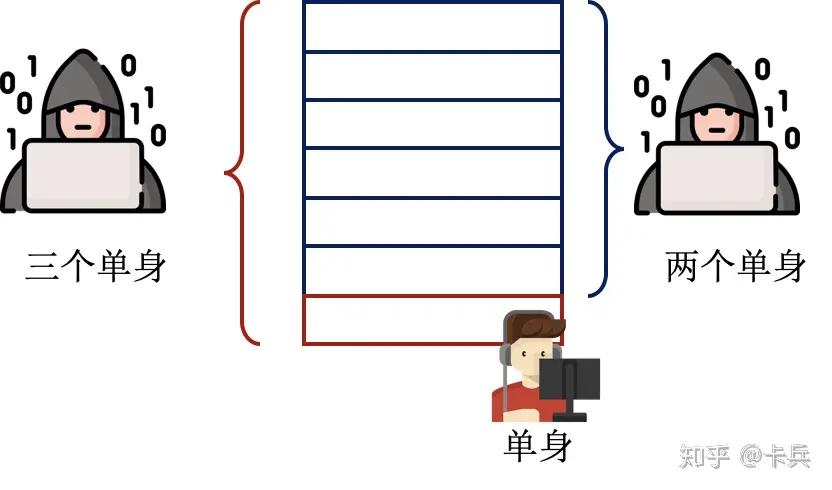
例如,有一张表记录着用户的姓名和性别,例如:<Alice, Female>。curator 提供查询 Male 数量和 Female 数量的接口:
- 攻击者查询一次 Male 数量。
- 此时数据表发生了变动,添加了一条记录为 <Bob, Male>,注意:假设攻击者知道 Bob 被添加进了数据库,但是不知道他的性别。攻击者想要知道这个信息。
- 攻击者再一次查询 Male 数量,将两次查询得到的结果做差,就能够判断出 Bob 的性别。
知乎上的科普文 Differential Privacy 简介 举了一个相似的例子。
Definition#
对于隐私定义的看法是多样的,其中一种常见的解释是将具体的用户 “hide in the crowd”,例如经典的 k - 匿名 算法就要求一个集合内至少要有 k 条记录具有相同的值。差分隐私的要求也是类似的,只是差分隐私要求的是随机算法给定输入和输出的概率是相近的。
**(differential privacy)** 给定任意两个相邻数据集 $X$ 和 $X'$(相邻可以指上文中假设的只插入一条用户数据的情况,当然也有其他更加抽象的解释),一个随机算法 $\mathcal {M}$,当对于任意可能的结果 $y$,都有
那么就称随机算法 $\mathcal {M}$ 满足 $\epsilon$-differential privacy($\epsilon$-DP)。一言蔽之,差分隐私要求返回相同结果的概率是相近的。显然,上文提到的聚合函数 $f$(count,sum,max)对应于这里的 $\mathcal {M}$,只是聚合函数给出的结果是确定的,不包含随机性,因此是不满足 $\epsilon$-DP 的。
和 k - 匿名类似,差分隐私给出了隐私定义,至于如何实现差分隐私,那就需要研究者来设计 $\mathcal {M}$ 的算法了。
Mechanism#
要对 $f$ 进行改造其实很简单,只需要在函数进行计算的过程中添加一些随机性。实际上,几乎所有差分隐私保护机制 $\mathcal {M}$ 都是围绕 “添加随机性” 这一核心展开的。
常用的添加随机性的方法主要有两大类:
- 向变量添加随机噪声,例如 Laplacian 噪声,高斯噪声,即
其中 $\Delta f$ 表示 $f$ 的敏感度,表示任意两个不同的 $X$ 下 $f$ 的差值的最大值。
- 使用随机响应(random response),即通过抛硬币的方式决定程序运行流程,可以想象成一个随机的 if 分支语句。
Properties#
差分隐私具有一些性质能够方便人们在现有算法的基础上进行组合和扩展,形成新的差分隐私扰动算法。

Local Differential Privacy#
Model#
要求用户的隐私能够得到差分隐私的保证,就需要这些 curator 对算法进行修改,添加随机性。在现实生活中,数据库持有者(curator)往往是那些提供服务的公司,要信任他们能够保护用户的隐私其实是不太现实的,他们没有把完整数据打包卖给第三方就不错了~
因此,研究者提出了更加严格的要求 —— 本地差分隐私(local differential privacy)。他将除自身之外的所有人都视作潜在的攻击者,包括 curator。
**(local differential privacy)** 给定任意(arbitrary)两个数据 $x$ 和 $x'$(这里不再是两个相邻数据集了,应为单个用户只对应一条记录),一个随机算法 $\mathcal {M}$,当对于任意可能的结果 $y$,都有
那么就称随机算法 $\mathcal {M}$ 满足 $\epsilon$-local differential privacy($\epsilon$-LDP)。与 DP 最大的区别是,LDP 是对客户端上的算法 $\mathcal {M}$ 提出了要求,在 DP 模型中,到达数据库的是用户的真实数据,而在 LDP 模型中,用户发送的已经是经过 $\mathcal {M}$ 处理之后的假(pseudo)数据(也就是公式中的 $y$)了。
显然,LDP 更能够让对隐私保护有要求的用户感到满意,因为整个宇宙中,除了他自己,没有人知道真正的数据。
Privacy Utility Tradeoff#
隐私(privacy)和效用(utility)是两个相对的概念,是天平的两端。效用反映了数据所能够提供的使用价值。当出于隐私保护的目的,对用户的数据进行一定的修改后,数据就会产生偏差,从而影响服务质量。例如 Location based Service(LBS)应用中,用户需要上传地理位置来享受服务(外卖、网约车、路径导航)。当服务方只能根据用户上传的假位置(pseudo location)来提供服务时,势必会带来一些麻烦(例如外卖送错了地点)。
因此,既要保证 privacy 又不能损失太大的 utility 就显得格外重要了,这也是研究隐私问题需要考虑的核心问题。在学术论文中,不仅要对隐私的收益和效用的损失做理论上的分析,还需要定义度量(metric)来对这二者的变化情况进行实验评估(empirically)。
对于效用而言,具体的效用度量取决于对于数据的类型和使用方式。
- 数值数据
- 计算均值等统计量。
- 区间统计(直方图)。
- 类别数据
- 频次统计。
- 找到频次最多类别(占多数的类别)。
- (其他)位置数据
- 附近 PoI(餐馆、公园、酒店等)查询 。
- 定位服务。
对于不同的应用,效用损失的计算方式是不同的,需要具体情况具体分析。往往一个算法,能够在保证隐私的情况下,确保一种特定应用场景下的效用损失不是太大,就已经很不错了。当然这里的衡量损失的大小不应该用绝对值,可以用多个不同算法的相对大小,也可以用倍率(类似渐进复杂度)的概念去衡量。
Application#
LDP 的应用是比较贴合移动互联网时代的用户体验的。一般的用户都会意识到服务方不太可信,因此保护措施如果在客户端进行的话更安全一些,有一些专业技能的用户则会去测试客户端发出的到底是不是经过处理过的数据(例如抓包)。

一些软件服务公司出于改进自身服务质量的目的,会收集用户的使用数据,像一些较为正规的大厂会弹出 “是否允许收集匿名使用数据” 的对话框让用户进行选择。这些数据会被用于分析出例如特定功能的使用频率等信息。例如 Apple 会统计 Emoji 的使用频率,并每年给出一份涵盖所有用户的使用报告,这个过程可以抽象成类别数据的统计过程。为了保证用户使用 Emoji 的隐私得到差分隐私保护,Apple 会对数据在本地和服务端做一些非常复杂的处理。具体过程被发布在了 Learning with Privacy at Scale - Apple Machine Learning Research 一文中。

另外,Google 也发布了其应用 LDP 的方案 RAPPOR。

这两家大公司的 LDP 方案的客户端部分很相似,可以总结为两点:
- 先用 Hash 函数将原始数据编码成二进制串。
- 用随机响应翻转每个二进制位。
当然,单条数据经过这些处理步骤之后,往往会变得 “面目全非”,但是当大量的面目全非的数据被服务器收集起来之后,服务端能够通过一定的算法来得到相对于真实值(频率、直方图等)较为接近的估计值。
目前的研究文献中,将 LDP 应用到生产环境中的之后 Google、Apple 和 Microsoft 这三家,这也是 LDP 的缺陷之一导致的 —— 要想获得较好的效用,需要极大的数据量。
Location Privacy

另一个 LDP 常见的应用是地理位置服务,在 LBS 的框架下,LDP 要求任意两个位置被混淆到相同位置的概率是相近的,但是要让北京和伦敦的两个位置被混淆到上海的概率相近,会造成巨大的效用损失,因此比较常用的做法如 Geo-Indistinguishability 一文所说:
概率的相似性与两个位置之间的距离直接关联。这样,以用户真实位置为圆心,半径为 r 的区域内的所有位置,可以看做一个等价类,这个等价类中的每个位置和用户真实位置被混淆到相同位置的概率是接近的,也就是上图所谓的” 模糊定位 “的范围。
Inference Attack#
提到 DP 就不得不提推断攻击(inference attack),攻击者基于已有的先验知识 $\pi$,以及公开的混淆机制 $\mathcal {M}$,推断出用户真实数据可能的分布。值得注意的是,(L)DP 并不能阻止推断攻击,因为推断攻击假设攻击者具有 $\pi$,而 DP 完全与 $\pi$ 无关,事实上,DP 的优势就在于他对任意 $\pi$ 下都适用。假设攻击者已经掌握了真实数据,即 $\pi (x_0)=1$,那么即便 DP 的要求多么苛刻,攻击者也能给出正确答案。
DP 的作用在于,仅根据 $\mathcal {M}$ 本身,攻击者无法得到任何额外的信息(information gain)。因为 $\mathcal {M}$ 对数据的混淆是带有随机性的,而这个随机的概率又相当的 “均匀”,所以攻击者仅凭 $\mathcal {M}$ 是无法准确地反推出真实数据的。但这不代表攻击者利用其他信息也不能准确反推数据。
已有好几篇论文对差分隐私的在具体应用场景下的局限性进行分析,如在地理位置隐私保护方面,存在:
- 不能抵抗推断攻击:如 PIVE。
- 随机性带来的效用损失极端情况:如 Back to the Drawing Board。
How to Water Paper#
根据我对 DP 相关学术研究的了解,DP 相关论文的难度如下依次递减:
- 提出新的 DP 模型(scheme)或者基础方法,如 shuffle model,amplification by resampling,vector DP 等,水这种论文需要很强的数学功底,需要推导出各种的上下界。
- 在挖掘到 DP 的缺陷之后,将 DP 与其他隐私保护概念结合。这类问题通常更考验对 privacy 和 utility 的理解。
- 将 DP 引入到具体应用中,如 LBS,群智感知,联邦学习等,将其作为优化问题的约束条件,或通过较为先进的 DP 模型来改进现有的工程实践,辅以理论分析(套公式)。
Summary#
DP 是理论性很强的概念,他对数据处理过程 $\mathcal {M}$ 的随机性提出了严格的约束,要求对于任意两个输入返回相同输出的概率是接近的。比起其他隐私概念,DP 更难被用户理解,要把隐私保护效果(包括随参数的变化)给出一个清晰直观的解释是较为困难的。